Learning to Continually Learn via Meta-learning Agentic Memory Designs
1University of British Columbia
2Vector Institute
3Canada CIFAR AI Chair
This project introduce ALMA (Automated meta-Learning of Memory designs for Agentic systems), a framework that meta-learns memory designs to replace hand-engineered memory designs, therefore minimizing human effort and enabling agentic systems to be continual learners across diverse domains. Our approach employs a Meta Agent that searches over memory designs expressed as executable code in an open-ended manner, theoretically allowing the discovery of arbitrary memory designs, including database schemas as well as their retrieval and update mechanisms.
Open-ended Exploration Process of ALMA.
The Meta Agent samples previously explored memory designs from an archive, where all explored memory designs and their evaluation logs are stored. Then the Meta Agent reflects on the sampled memory designs to generate new ideas and plans, which are implemented in code. The new designs are subsequently validated and evaluated, with the resulting logs added back to the archive to guide future sampling.
Example of Learning Process
We include an example learning process for the first six memory designs in Baba Is AI. The full learning process is available in our paper. The memory design archive tree illustrates how discovered memory designs are archived and structured during open-ended exploration. ALMA progressively discover new memory designs built on an ever-growing archive of previous discoveries.
Results
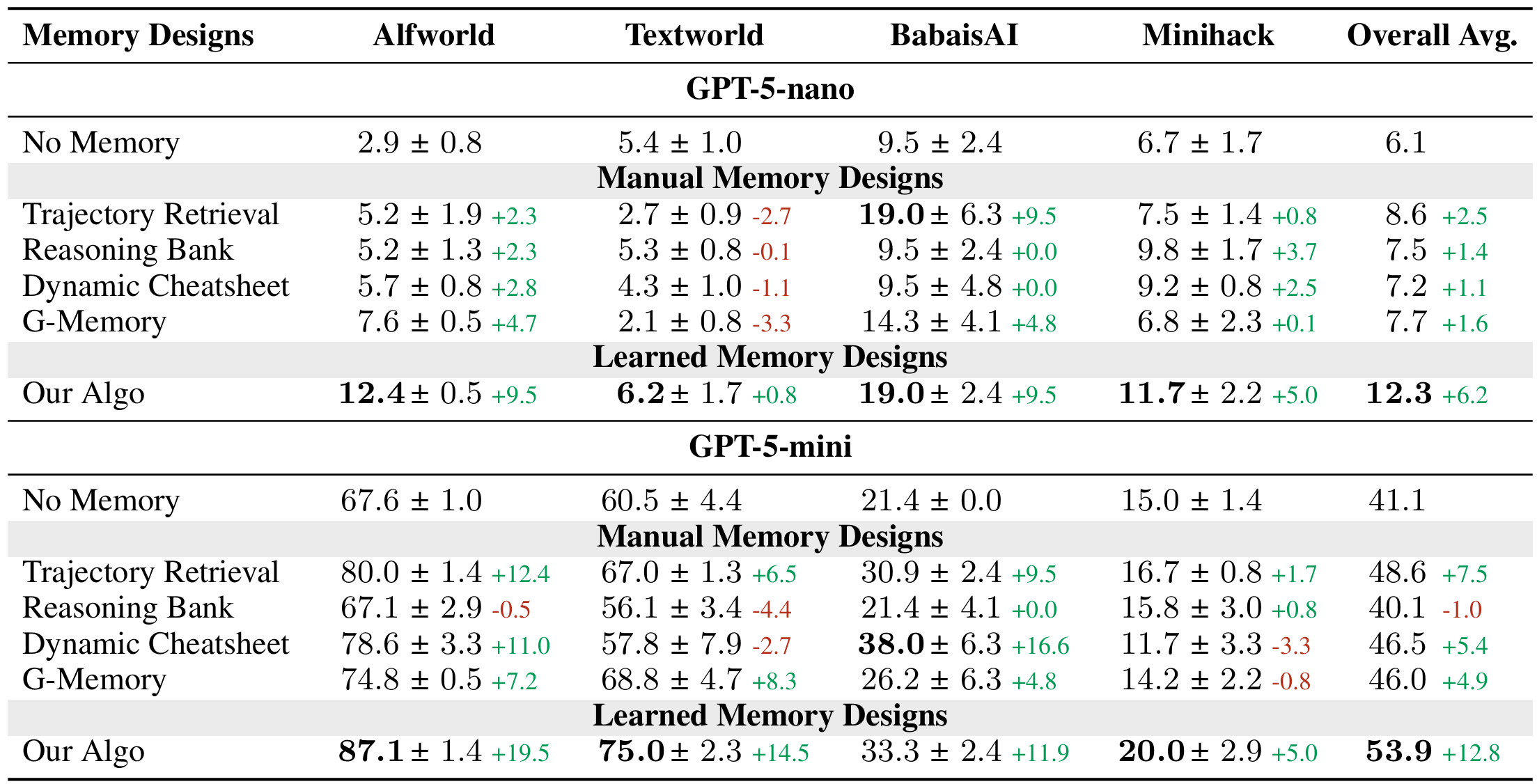
Comparison of success rates between the learned memory designs and baseline memory designs across environments.
The learned memory designs consistently outperform the all state-of-the-art human-designed memory baselines across benchmarks. This holds for agentic systems powered by both GPT-5-nano and GPT-5-mini, demonstrating that the discovered memory designs can more effectively store and reuse past experience to support continual learning of agentic system during test time. Moreover, the performance gains become more pronounced with a more capable foundation model, indicating that our learned memory designs generalize across different FMs and provide stronger support as the underlying agentic system becomes more powerful. Overall, these results show that the improvements are robust and not tied to a specific model, highlighting the scalability and generality of our approach.
The visualization of the best-learned memory designs across different benchmarks.
Each sub-module in memory designs may have a dedicated database or none, depending on its function, and arrows show the retrieval and update workflows in memory designs. The name and explanation of each sub-module are generated by Meta Agent and manually summarized, respectively.
The learned memory designs that ALMA discovers effective memory structures adapted to diverse task requirements. For games with explicit object interaction goals (e.g., ALFWorld and TextWorld), the learned memory designs tend to store fine-grained knowledge, such as spatial relationships between objects and room layouts. In contrast, for tasks that require more complex reasoning (e.g., Baba Is AI and MiniHack), the memory designs favor domain-specific abstract strategy, including strategy libraries and plan synthesis. This pattern indicates that ALMA automatically specializes memory designs to the demands of each domain.
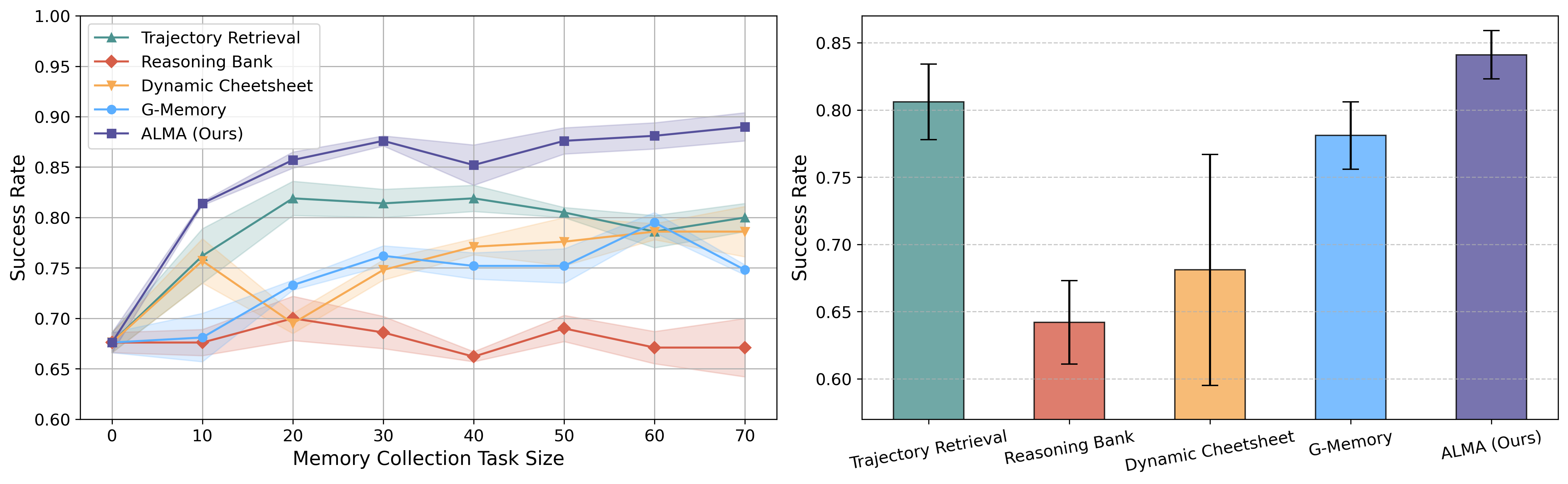
Comparison of memory designs in ALFWorld. Left: Success rates as the memory size increases. Right: Success rates under task distribution shift.
Compared to manual memory designs, the learned memory design achieves higher performance faster with limited data and scales better as more trajectories are provided, demonstrating both higher sample efficiency and stronger scalability. The learned memory design also outperforms all human-designed baselines and demonstrating more effective adaptation under task distribution shift.